Generative AI Models: VAEs, GANs and Diffusion
Generative AI doesn't understand anything. It's learning patterns in data and playing them back in new combinations. Everything else is details about how to make that work.

menu_book In this lesson expand_more
Generative AI doesn't understand anything. It's learning patterns in data and playing them back in new combinations. Everything else is details about how to make that work.
The actual problem is hard though. If you want a machine to create new images, music, or text that doesn't exist in your training data, you need a way to learn what makes those things valid - not memorise the training set.
What generative models are trying to do
A generative model learns a probability distribution. It's learning P(x) - the probability of seeing something like x. Once it learns that distribution, you can sample from it to create new things.
This matters because you can't just memorise. Your training set might have a million images, but the space of possible images is infinite. The model has to compress what it learns into something that can generate novel examples.
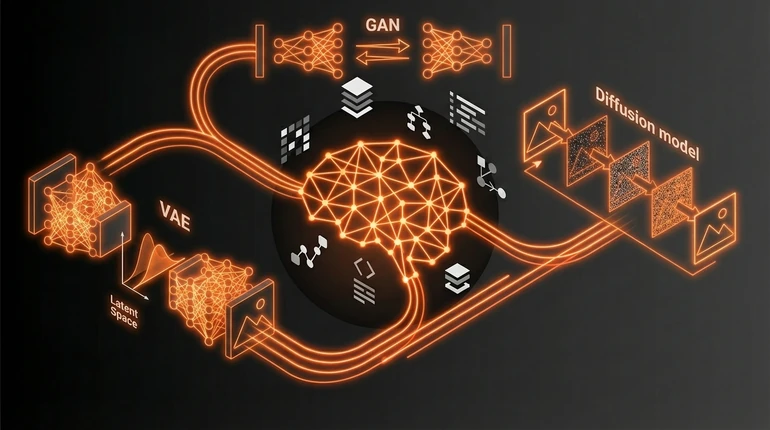
Variational Autoencoders (VAEs)
VAEs work in two pieces. The encoder compresses an image down to a small vector of numbers - a latent representation. The decoder reconstructs the image from that vector.
The clever part is what happens in the middle. VAEs don't learn a fixed compression. They learn a distribution over possible latent codes. The encoder outputs a mean and variance, and you sample from that distribution. Then you decode the sample.
This forces the model to learn a smooth latent space. Move slightly in that space, and the decoded image changes smoothly. You can interpolate between two images by interpolating in latent space.
VAEs are mathematically elegant - you can write down and understand why they work. But the images they generate often look blurry. The model is averaging over possibilities rather than committing to sharp details.
GANs: the generator vs discriminator game
GANs are adversarial. Two networks fight each other. The generator creates fake images from random noise. The discriminator tries to tell which images are real and which are fake.
If the discriminator gets too good, the generator has to make more convincing fakes. If the generator gets too good, the discriminator can't tell the difference. In theory they reach a Nash equilibrium where the generator produces indistinguishable samples.
This was genuinely exciting when it came out. GANs could produce sharp, detailed images in ways VAEs couldn't. People built increasingly sophisticated GAN architectures and got impressive results.
But GANs are hard to train. The adversarial dynamic is unstable. Mode collapse happens - the generator learns to produce a few variations really well instead of the full diversity of the training distribution. Training requires careful tuning, careful architecture choices, and often luck. Most practitioners working with images today aren't using GANs. The technology works but it's temperamental.
Diffusion models: the dominant approach
Diffusion models solve image generation differently. They start with random noise and gradually denoise it over many steps.
Take an image and add noise to it repeatedly until it's pure random noise - that's the forward process. Then train a model to reverse it: to predict what the image was before the last noise was added.
If you can predict denoising at every step, you can start from pure noise and iteratively denoise. Each step removes a little noise until you have a generated image.
This is simple. Elegantly simple. The training objective is clear - predict the noise that was added. It's not adversarial, so there's no mode collapse. You get as much diversity as your training data had.
The trade-off is speed. Sampling requires many steps - maybe 50 to 1,000 denoising steps, versus one forward pass for a VAE or GAN. But over the last few years, researchers have developed better sampling algorithms that dramatically reduced the number of steps needed without losing quality.
Why diffusion won
Diffusion models became dominant for a simple reason: they work reliably and they scale. They're stable to train. Mode collapse isn't a problem. You get good diversity. The maths is clean.
GANs can generate quickly, which matters in some applications. VAEs are mathematically elegant and have a clean probabilistic interpretation. But if you're building an image generation system today, you're probably starting with diffusion.
If you're learning generative models to understand what's happening under the hood, VAEs are worth understanding - the latent space interpretation is genuinely useful. GANs are interesting historically; they opened up adversarial training as a concept that matters beyond just image generation. But diffusion is what's shipping and what's driving progress. For text generation, transformer-based models dominate - diffusion applies mainly to images, audio, and video.
The interesting questions now aren't which model type is best. They're how to make diffusion faster and how to control what gets generated - prompting and conditioning. Techniques like RAG and fine-tuning build on top of these generative foundations. The foundation work is largely solved.
Check your understanding
2 questions - select an answer then check it
Question 1 of 2
Why do diffusion models produce sharper images than VAEs?
Question 2 of 2
What is the main reason GANs are less commonly used for image generation today?